Apache Kafka очень производительный инструмент, который нужен для перенаправления потоков данных из одного места в другое, с обработкой и без. Проект достаточно зрелый, и среди тех, кто его активно использует, много гигантов IT индустрии: LinkedIn, Netflix, Yahoo, Twitter, Pinterest, и другие. Проект стал невероятно популярным во многом благодаря своим неоспоримым преимуществам: легкость настройки, масштабируемость, высокая пропускная способность и надежность.
В отличие от обычных брокеров, которые удаляют сообщения сразу же после успешной доставки, Kafka хранит их столько, сколько скажут. По умолчанию — неделю. Это удобно, потому что, подписываясь на топик в Kafka можно получить и те сообщения, которые публиковались позавчера. Цифры попадаются разные, но Kafka превосходит по производительности многие популярные брокеры вроде ActiveMQ и RabbitMQ. По некоторым источникам зафиксированная пропускная способность Кафки: 100K сообщений в секунду, а у RabbitMQ всего 20К.
Кафке нужен вспомогательный сервис для того, чтобы координировать работу всех своих брокеров в кластере, и имя тому сервису — ZooKeeper. Когда создаётся новый топик, или добавляется новый брокер, или удаляется старый, ZooKeeper — это тот, кто будет со всем этим разбираться. Он решит, куда положить новый топик, чем загрузить нового брокера, и даже как сбалансировать набор реплик, если часть из них ушла вместе с павшим сервисом. Он надсмотрщик и координатор, и его запускают первым
Apache Zookeeper обеспечивает координацию брокеров в кластере. Топики с сообщениями можно разбить на разделы (partition) и распределить внутри кластера, а затем еще включить и репликацию. На выходе вырастет пропускная способность, ведь один топик теперь хранится и обслуживается несколькими брокерами, и даже если один из брокеров умрёт, где-то останется реплика его данных, и всё обойдётся без потерь. Хотя некоторые очереди сообщений тоже умеют делать репликацию, я не могу вспомнить ни одной, которая умеет дробить свои очереди на части и распределять по кластеру. Partitions — единица. То есть наш топик будет храниться в одном монолитном хранилище. Если вдруг топик будет большим — больше, чем позволяет файловая система, и/или хост, который его держит, может и справиться со всеми входящими запросами, то его можно разбить на несколько разделов, которые, скорее всего, окажутся на разных хостах. Если еще включить репликацию, то получится удивительной надежности кластер.
Replication-factor 1. «Один» означает, что будет только одна копия топика, и если хранящий его хост уйдёт в никуда, данные пойдут следом. С другой стороны, если бы у нас было два хоста, и коэффициент тоже выбрали «2», то каждый хост получил бы свою копию топик
- «Leader» — это узел, ответственный за все чтения и записи для данного раздела. Каждый узел будет лидером для случайно выбранной части разделов.
- «Replicas» — это список узлов, которые реплицируют журнал для этого раздела независимо от того, являются ли они лидером или даже если они в настоящее время живы
Загрузим дистрибутив kafka с сайта kafka.apache.com.
Распакуем архив в директорию Desktop .
Произведем установку Java 1.8.

Запустим zookeeper-server следующей командой.
bin/zookeeper-server-start.sh config/zookeeper.properties
Запустим kafka-server следующей командой:
bin/kafka-server-start.sh config/server.properties
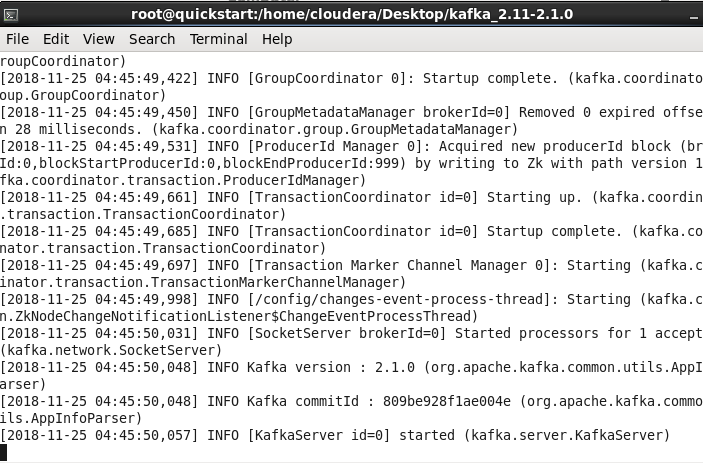
Запустим топик следующей командой :
kafka-topics —zookeeper localhost:2181 —create —topic MyTopic —partitions 1 —replication-factor 1

Проверим работоспособность топика следующей командой: bin/kafka-topics.sh —zookeeper localhost:2181 —listtest-topic
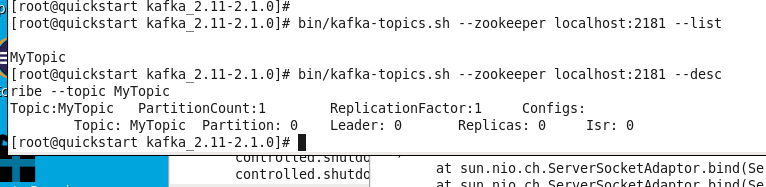
bin/kafka-console-consumer —bootstrap-server localhost:9092 —topic MyTopic
Запуск потребителя Запустим производителя: bin/kafka-console-producer.sh —broker-list localhost:9092 —topic MyTopic
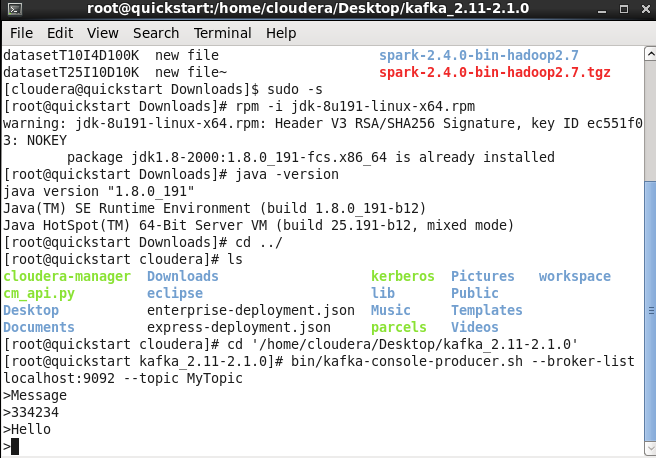
Запустим кластер с несколькими брокерами. Чтобы избежать столкновения, мы создаем файл server properties для каждого брокера и изменяем свойства конфигурации id port и logfile (рисунок 10).

Создадим два файла командой:
cp config/server.properties config/server-1.propertiescp config/server.properties config/server-2.properties
Добавим значение:
broker.id=1listeners=PLAINTEXT://:9093log.dirs=/usr/local/var/lib/kafka-logs-1broker.id=2listeners=PLAINTEXT://:9094log.dirs=/usr/local/var/lib/kafka-logs-2
Запустим брокер
bin/kafka-server-start.sh config/server.properties & bin/kafka-server-start.sh config/server-1.properties & bin/kafka-server-start.sh config/server-2.properties
Создадим реплицированную тему
bin/kafka-topics.sh —zookeeper localhost:2181 —create —replication-factor 3 —partitions 1 —topic replicated-topicbin/kafka-topics.sh —zookeeper localhost:2181 —describe —topic replicated-topicTopic:replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:Topic: replicated-topic Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
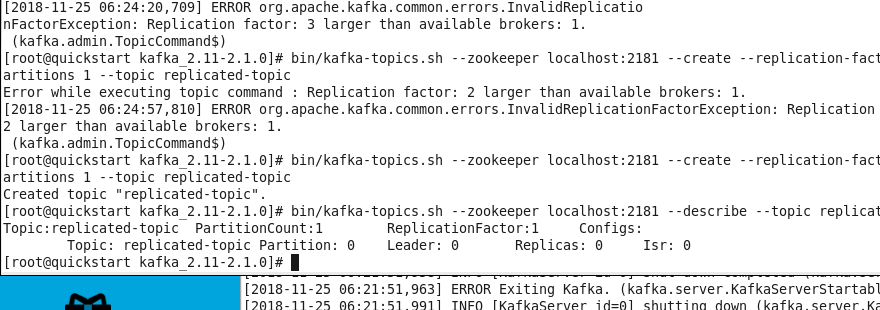
Самостоятельно попробуем отправить сообщения с помощью клавиш