Райффайзенбанк проведет онлайн-хакатон по созданию решений для малого и среднего бизнеса. Цель соревнования — найти новые идеи продуктов для малого и среднего бизнеса по одному из предложенных треков. Принять участие можно только командой от 3 до 5 человек.
Для централизации финансовой деятельности необходимо обработать выписки формата 1CClientBankExchange в формат собственной банковской системы (например записать в базу данных MS SQL или Oracle ). В частности подобные файлы обрабатываются в крупных корпорациях и финансовых организациях.
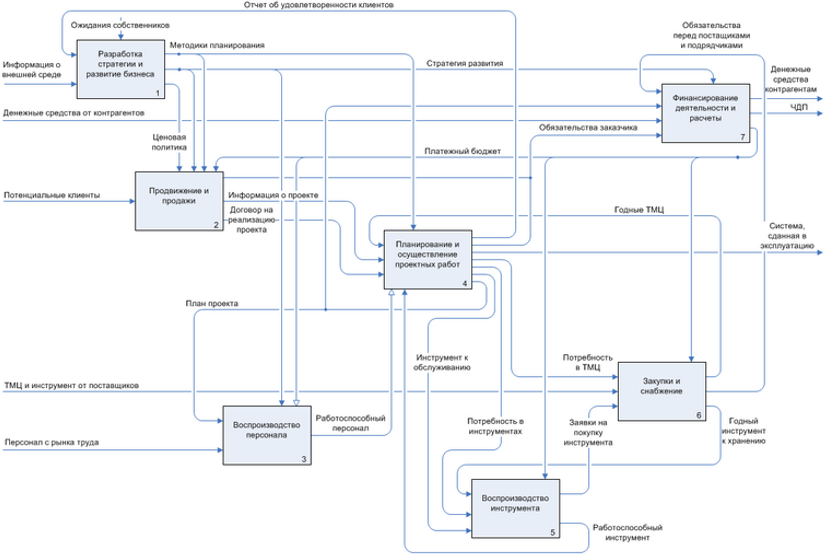
Первоначально мы имеем сетевую файловую структуру следующего вида
В папку «IN» поступают банковские выписки и после обработки попадают в папку «Archive».
Дополнительно необходимо предусмотреть папку «Error» для ошибочных файлов и папку «Log», где будут вестись логи обработки.
Программа будет написана на языке C#.
Кодировка исходных файлов — Windows-1251. Обработка файла выполняется следующем образом. Мы анализируем каталог, получаем общее количество файлов, потом возвращаемся к первому файлу, разбиваем строку на массив элементов по разделителю «=». После обработки файла он перемещается в архив, исходный файл удаляется.
public static bool ReadFile(string filename)
{
var srcEncoding = Encoding.GetEncoding(1251);
var dstEncoding = Encoding.UTF8;
bool success = false;
try
{
using (StreamReader sr = new StreamReader(filename, encoding: srcEncoding))
{
string headers = sr.ReadLine();
int count = System.IO.File.ReadAllLines(filename).Length;
int i = 0;
logger.Debug("Чтение данных");
PaymentP paymentP = new PaymentP();
while (i < count)
{
string onedouble = sr.ReadLine();
if (Check(onedouble) == true)
{
string[] lines = Regex.Split(onedouble, "[=]");
if (lines[0] != null)
{
if (lines[1] != null)
{
logger.Debug($"{lines[0]} {lines[1]}");
paymentP.TranslateToexport(lines[0], lines[1]);
i++;
success = true;
}
if (lines[1] == null)
{
logger.Debug($"{lines[0]}");
i++;
success = true;
}
}
}
else
{
i++;
success = true;
}
}
Export(paymentP);
paymentP=null;
}
}
catch
{
logger.Debug("Ошибка чтения файла");
}
return success;
После обработки данные записываются в структуру
public class PaymentP { public string Otpravitel; public string Poluchatel; public DateTime DataSozdaniya; public DateTime VremyaSozdaniya; public string RaschSchet; public string Dokument; public string Nomer; public DateTime Data; public string Summa; public string PlatelshchikSchet; public string PlatelshchikINN; public string PlatelshchikKPP; public string Platelshchik1; public string PlatelshchikRaschSchet; public string PlatelshchikBank1; public string PlatelshchikBank2; public string PlatelshchikBIK; public string PlatelshchikKorschet; public string PoluchatelSchet; public string PoluchatelINN; public string Poluchatel1; public string PoluchatelRaschSchet; public string PoluchatelBank1; public string PoluchatelBank2; public string PoluchatelBIK; public string PoluchatelKorschet; public string VidPlatezha; public int VidOplaty; public int Ocherednost; public string NaznacheniePlatezha;
И обращаемся к конкретному полю ( реализация вывода выполнена в ознакомительных целях).
Настройки корневого пути файлов мы будем хранить в реестре операционной системы.
Обработанные поля в консоль выводятся следующем образом (для проверки).
При создании современных рекомендательных систем одной из задач является поиск ассоциативных правил, позволяющих при анализе корзин покупок рекомендовать очередные, вероятно необходимые покупателю, товары. Аналогично, при анализе последовательностей изученных курсов или запрошенных компьютерной программой массивов данных можно рекомендовать очередные курсы или массивы данных для обработки или анализа.
Для поиска подобных ассоциативных правил необходимо сначала находить последовательные шаблоны (Sequential Pattern Mining) – цепочки купленных товаров или запрошенных файлов, и затем исследуя их строить устойчивые ассоциации.
К настоящему времени для решения этой задачи разработано несколько алгоритмов, с разной степенью эффективности анализи-рующих различные типы последо-вательности товаров и услуг.
Одним из наиболее эффективных алгоритмов поиска ассоциативных правил является алгоритм FP-growth(https://basegroup.ru/community/articles/fpg). Его название можно перевести как «выращивание популярных (часто встречающихся) предметных наборов». Этот алгоритм позволяет не только избежать затратной процедуры генерации кандидатов, но и уменьшить необходимое число проходов по базе данных предметных наборов до двух.
В основе метода лежит предобработка базы транзакций, путем преобразования ее в компактную древовидную структуру, называемую Frequent-Pattern Tree – дерево популярных предметных наборов (откуда и название алгоритма). В дальнейшем для краткости будем называть эту структуру FP-дерево. К основным преимуществам данного метода относятся:
Сжатие БД транзакций в компактную структуру, что обеспечивает очень эффективное и полное извлечение частых предметных наборов;
При построении FP-дерева используется технология разделения и захвата (divide & conquer), которая позволяет выполнить декомпозицию одной сложной задачи на множество более простых;
Позволяет избежать затратной процедуры генерации кандидатов, характерной, например, для алгоритма «a priori».
заключается в том, чтобы найти в заданной базе предметных наборов все часто встречающиеся предметы и добавить их к текущему шаблону, получая новые частые последовательности. После этого можно искать частые последовательности большей длины на основе проецированных баз данных. Создание проецированных баз может сильно ухудшить производительность при работе с большими объемами данных, поэтому вместо физического создания проекций, используется псевдопроецирование (pseudoprojection).
При рекурсивном вызове метода PrefixSpan вместо созданной проекции ему передаются указатели на минимальные позиции возможных вхождений предметов в клиентские последовательности после текущего шаблона. В качестве указателя рассматривается набор, состоящий из идентификатора клиента, номера транзакции в клиентской последовательности и позиции в транзакции. Благодаря псевдопроекции, скорость работы алгоритма значительно повышается. Кроме того, для работы алгоритма требуется значительно меньше памяти.
Работа с алгоритмами FP—growthи PrefixSpan
Действия:
А) Скачиваем предоставленные тестовые файлы с указанного диска.
Немного о выборках:
Имеем шесть выборок с разными параметрами (см. рис. 4.2):
— среднее число транзакций (T) для неоднородных баз или точное число транзакций для однородных баз (С) в клиентских последовательностях,
— среднее число предметов в транзакциях (I),
— количество клиентских последовательностей (D).
Копируем файлы с выборками в hadoop. Делаем так же, как уже делали в лабораторной работе № 2 (пункт 2.2.-> Создание таблиц):
Рис. 4.3. Результат копирования файлов с выборками.
Б) Тестируем алгоритм FP-growth
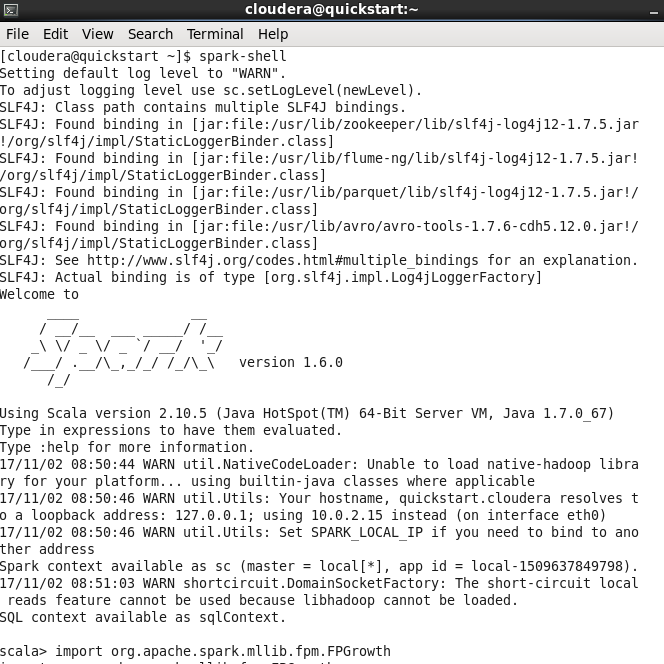
Запускаем Apache Spark командой spark–shell (в разных версиях Spark разные команды, ещё одна из них: spark2–shell) в терминале системы и ждём пока появится строка scala> (в нижней части экрана на рис. 4.4)
Рис. 4.4. Результат запуска Spark.
Вводим в терминал системы код заранее написанной программы:
import org.apache.spark.mllib.fpm.FPGrowth
import org.apache.spark.rdd.RDD //импортируем библиотеки
}//Для полученных последовательностей ищем ассоциативные правила и выводим их.
Так же можно создать файл. В него скопировать текст программы и запустить его командой (лучший вариант запуска, так как в дальнейшем нужно будет редактировать код)
Оцениваем результат. Создаём файл на рабочем столе, куда копируем результаты выполнения программы. Аналогично делаем для разных выборок, измеряя время работы программы с помощью функции: System.currentTimeMillis()). Для этого в самое начало выполнения программы пишем команду:
val t0 = System.currentTimeMillis()
и получаем время, которое было на момент запуска программы. Далее в конце программы (до вывода результатов) выполняем команду: println(System.currentTimeMillis() – t0). Результаты заносим в заранее созданную для этого Excel–таблицу (рис. 4.6).
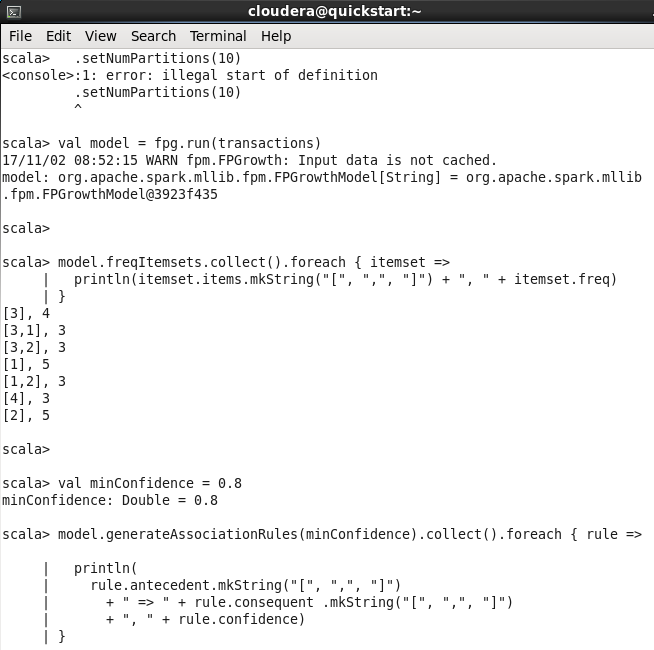
Рис. 4.5. Результат запуска программы с алгоритмом FPGrowth.Рис. 4.6. Время работы алгоритма FPGrowth.
Если еще осталось время, можно, изменяя минимальные поддержку (MinSupp) и достоверность (MinConf), получить результаты для разных случаев.
В) Тестируем алгоритм PrefixSpan
Вводим код программы в терминал системы:
import org.apache.spark.mllib.fpm.PrefixSpan //импортируем библиотеки
val sequences = sc.parallelize(Seq(
Array(Array(1, 2), Array(3)),
Array(Array(1), Array(3, 2), Array(1, 2)),
Array(Array(1, 2), Array(5)),
Array(Array(6))
), 2).cache() //задаём последовательности
val prefixSpan = new PrefixSpan()
.setMinSupport(0.5) //Изменяемое значение параметра MinSupp
.setMaxPatternLength(5)
//заводим переменную, отвечающую за работу алгоритма PrefixSpan, где указываем MinSupp и MaxPatternLength
val model = prefixSpan.run(sequences) )//запускаем алгоритм PrefixSpan с указанными выше параметрами
Выборки приходится вставлять непосредственно в код (3-я строчка) после команды: val sequences = sc.parallelize (Seq(.
Чтобы не работать руками, пишем на любом языке программирования парсер для стандартных форматов. Если есть трудности с написанием, то пишем этот парсер в любом текстовом редакторе, например, NotePad++.
Можно распарсить выборку и самостоятельно
Формат входных данных для алгоритма JavaRDD<List<List<Integer>>>
Пример. Есть выборка:
1 2 3
4 5 6
7 8 9
Открываем файл с выборкой в Notepad++. Открываем замену символов. Заменяем пробелы на запятые. Заменяем начало строки на — Array(Array(. Конец строки заменяем на — )), Копируем полученное в код программы и запускаем.
Результаты так же заносим в excel-таблицу и файл.
Здесь можно также изменять минимальную поддержку (MinSupp).
4.3. Сравнение алгоритмов
Сравниваем время работы алгоритмов на одних и тех же выборках. Находим отличия.
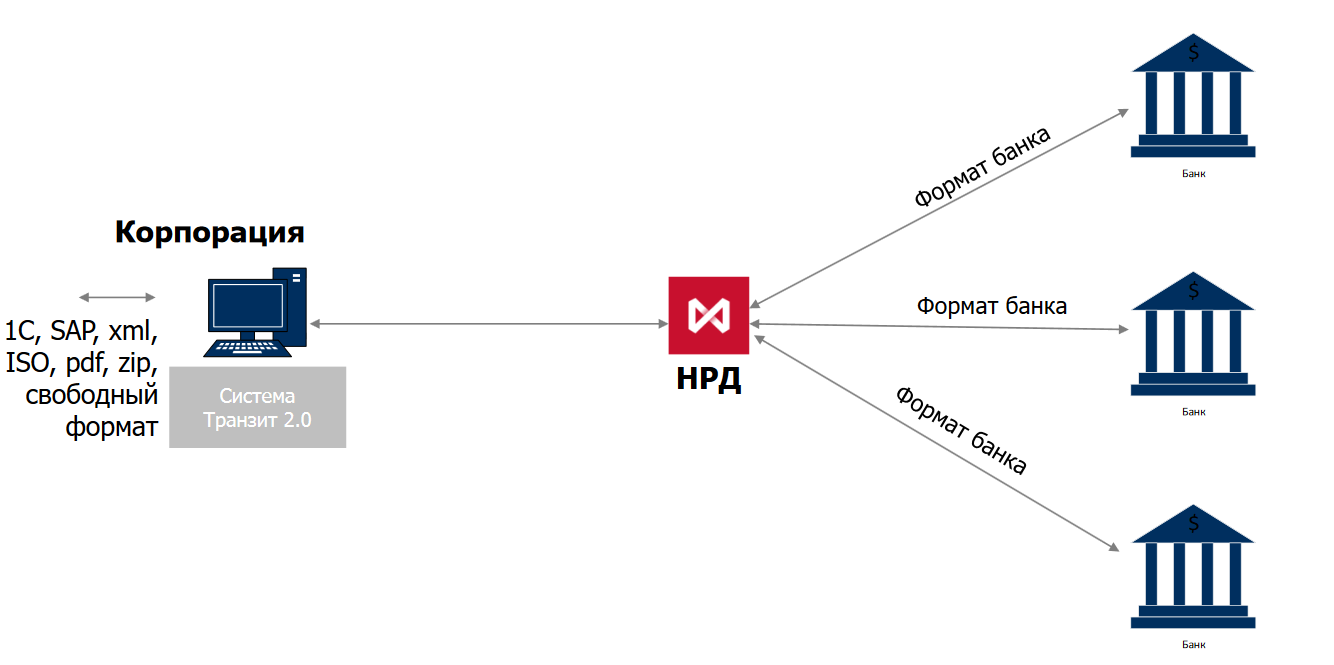
Транзит 2.0 — это обновлённая система для обмена финансовыми сообщениями между корпорациями и банками, разработанная Национальным расчётным депозитарием на основе предыдущей версии — Транзит. До сих пор её основными пользователями были лишь профессиональные участники рынка ценных бумаг, обменивающиеся электронными документами друг с другом в процессе депозитарной деятельности и проведения денежных расчётов. Транзит 2.0 значительно расширяет список и возможности пользователей: систему могут использовать корпорации и банки для автоматического обмена платёжными и иными документами, включая сообщения в международном формате ISO 20022.
Транзит электронных документов через СЭД НРД обеспечивается только при условии использования отправителем и получателем одинакового типа СКЗИ (или только сертифицированных СКЗИ, или только не сертифицированных СКЗИ).
При транзите электронных документов стороной-отправителем может использоваться схема с «открытым конвертом» или схема с «закрытым конвертом».
При использовании схемы с «открытым конвертом» передаваемые электронные документы не зашифровываются. Зашифровыванию с использованием открытых ключей шифрования НРД подвергается только Пакет транзитных электронных документов. При использовании схемы с «открытым конвертом» передаваемые электронные документы могут быть расшифрованы НРД, что позволяет НРД контролировать структуру (формат, спецификацию) передаваемых файлов и гарантирует получателю получение корректного по структуре (формату, спецификации) документа.
При использовании схемы с «закрытым конвертом» отправляемые электронные документы после формирования зашифровываются с использованием открытых ключей шифрования получателя, а затем Пакет транзитных электронных документов зашифровывается с использованием открытых ключей шифрования НРД. Такая схема не позволяет получить доступ к информации со стороны НРД.
На сегодняшний день в системе возможны переводы только рублёвых платежей, валютные операции недоступны.
Участниками данной системы является: ГК «Дикси», АО «Газпромбанк», АО «Альфа банк», — других участников данной системы не обнаружено.
Владельцем системы является Национальный Расчётный Депозитарий;
Для более подробного ознакомления с возможностями системы Business Studio 5 мы приглашаем Вас на официальную презентацию новой версии, которая пройдет 8 и 9 октября 2020 в формате онлайн.