К концу XXI века объем информации превысит 4,22 йоттабайт (или 4,22*1024 степени). А объем интернет-трафика перешел уже отметку в один зеттабайт и через пару лет составит несколько зетттабайт. Эту информацию необходимо обработать и представить в читаемый вид.
Но для этих задач необходимо нанять дорогостоящих специалистов, купить специализированное программное обеспечение. И тут на помощь могут прийти Open Source решения — их не так много, но есть очень достойное ПО, одним из которых которых является RapidMiner. RapidMiner (далее просто «майнер») — инструмент, созданный для дата майнинга, с основной идеей, что майнер (аналитик) не должен программировать при выполнении своей работы. При этом как известно, для майнинга нужны данные, поэтому его снабдили достаточно хорошим набором операторов решающих большой спектр задач получения и обработки информации из разнообразных источников (базы данных, файлы и т.п.), и можно с уверенностью говорить, что это ещё и полноценный инструмент для ETL ( Extract, Transform, Load).

RapidMiner — это мощная и многопользовательская платформа, она служит для создания, передачи и обслуживания наукоемких данных. Платформа RapidMiner предлагает больше функций, чем любое другое визуальное решение, плюс она открыта и расширяема для поддержки всех потребностей научных данных.
Унифицированная платформа RapidMiner ускоряет создание полных аналитических рабочих процессов — от подготовки данных до моделирования до развертывания бизнеса — в единой среде, значительно повышая эффективность и сокращая время, необходимое для проектов в области данных.
Профессиональная лицензия платная. В стандартной лицензии AGPL доступно 10,000 колонок и ограничение в один логический процесс.
- Хороший GUI. По сути, каждый функциональный блок собран в кубик. Ничего нового в подходе, но очень крутое исполнение. Обычно разница между классическим программированием и визуальным сильно бьёт по функциональности. Например, в SPSS Modeler всего 50 узлов, а тут целых 250 в базовой загрузке.
- Есть хорошие инструменты подготовки данных. Обычно предполагается, что данные готовятся где-то ещё, но тут уже есть готовый ETL (получение и трансформация). В том же коммерческом SPSS возможностей для подготовки куда меньше.
- Расширяемость. Есть язык программирования R. Полностью интегрированы операторы система WEKA.
- Дружит с Hadoop (отдельное платное расширение с незамысловатым названием Radoop), причём как с чистым, так и с коммерческими реализациями.
- Архитектурно данные снаружи. Ставим платформу, грузим данные и начинаем смотреть, где какие кореляции, что можем спрогнозировать. Это и плюс, и минус, почему — ниже.
- Кроме IDE есть ещё сервер. Rapid Miner Studio создаёт процессы, а на сервере их можно публиковать. Что-то типа Cron — сервер знает, какой процесс когда запускать, с какой частой, что делать, если где-то что-то отвалилось, кто отвечает за каждый из процессов, кому как отдавать ресурсы, куда выгружать результаты.
- А ещё сервер же умеет сразу строить минимальные отчёты. Можно выгружать не в XLS, а рисовать графику прямо там. Это нравится маркетингу маленьких проектов.
- Быстрое развитие. Только поднялся серьезный шум вокруг Apache Spark — через месяц интегрировали.
Если сравнивать RapidMiner c другими программами, то у RM гораздо шире функциональные возможности по обработке, банально больше узлов. С другой стороны, в IBM SPSS есть режимы «автопилота». Авто-модели (Auto Numeric, Auto Classifier) — перебирают несколько возможных моделей с разными параметрами, выбирают несколько лучших. Не сильно опытный аналитик может построить на таком адекватную модель. Она почти наверняка будет уступать в точности построенным опытным специалистом, но есть сам факт — можно построить модель ничего не понимая в этом. В RM есть аналог (Loop and Deliver Best), но он все же требует хотя бы выбрать модели и критерии выбора лучшего. Автоматическая предобработка данных (Auto Data Prep) — другая известная фишка SPSS — иначе и чуть более муторно реализована в RapidMiner. В SPSS сборка данных выполняется одним узлом Automated Data Preparation, галочками проставляется, что нужно сделать с данными. В RapidMiner — собирается из атомарных узлов в произвольной последовательности.

Если сравнивать с SAS. По возможностям «сделать что угодно» RM выше, но, в конечном итоге, с помощью какой-то матери и некоторых усложнений можно получить тот же результат и в SAS. Но здесь совершенно другой подход — придётся переучиваться, если вы привыкли к SAS. Ещё SAS предоставляет множество вертикальных решений — банки, ритейл. Платформа разговаривает с пользователем на его бизнес-языке. RM более абстрактен, в нём придётся самому формулировать, что есть что.
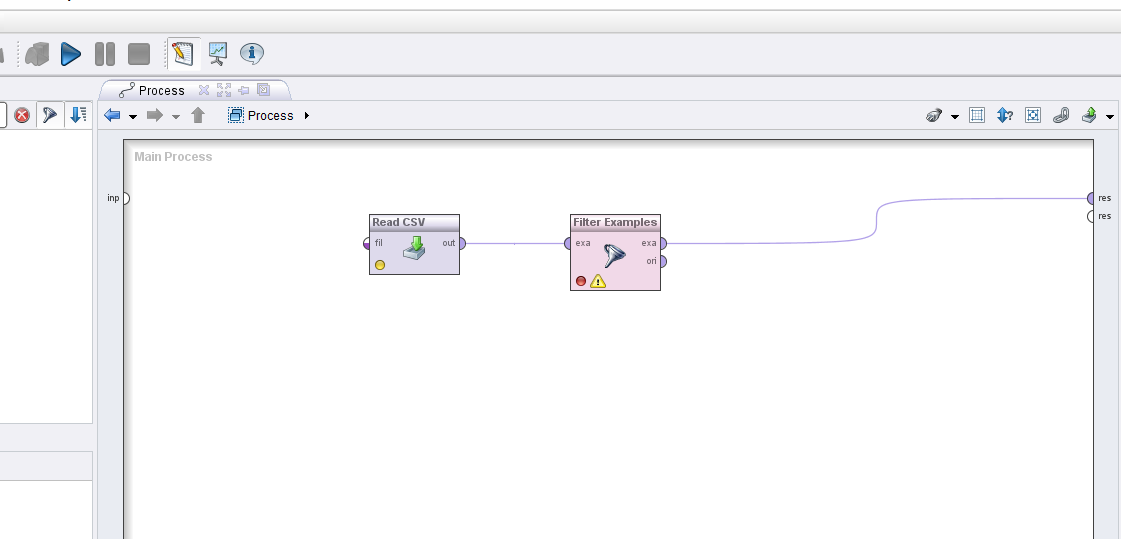
Процесс в RapidMiner представляет собой набор операторов, соединенных последовательно между собой. Есть операторы, которые считывают данные из файла, есть операторы, которые производят фильтр по определенным признакам, есть операторы, которые записывают результат в файл, и многие другие.
Оператор — это логическая единица, которая может производить какое-то действие над данными. Оператор имеет вход и выход. На входе поступают сырые данный, на выходе получаются обработанные данные. Все операторы доступны в левой колонке и отсортированы по функциональному признаку.
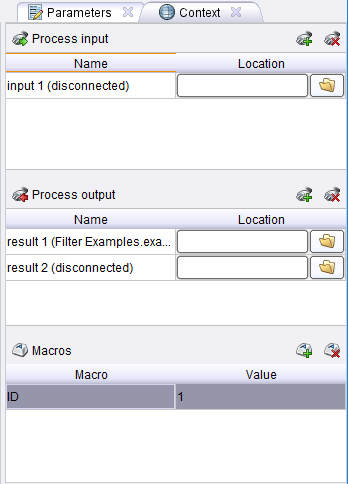
Еще одна интересная особенность RapidMiner от IBM SPSS и SAS. В RapidMiner есть макросы — это параметры работы процесса, которые можно использовать в любой его точке (т.е они являются глобальными переменными). Например, в качестве макроса можно использовать имя файла, дату его создания, среднее значение какого-либо атрибута данных, наилучшую достигнутую точность, номер итерации, последнее время запуска процесса.
Место для хранения процессов RM. Может быть локальным, а также удаленным (RapidMiner Server), для которого возможно исполнять процессы на стороне сервера, многопользовательский доступ к процессам/соединениям БД, запуск процессов по расписанию или отдача данных как веб-сервис.
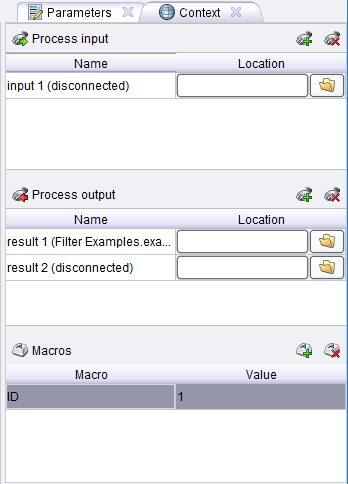
Кроме Макроса во вкладке контекст присутствуют параметры process input и process output.
process input- данных, подающиеся на вход. Может быть указан путь откуда вытаскивать данные.
process output. — данные, которые передаются к следующему процессу. Может быть указан путь для сохранения данных.
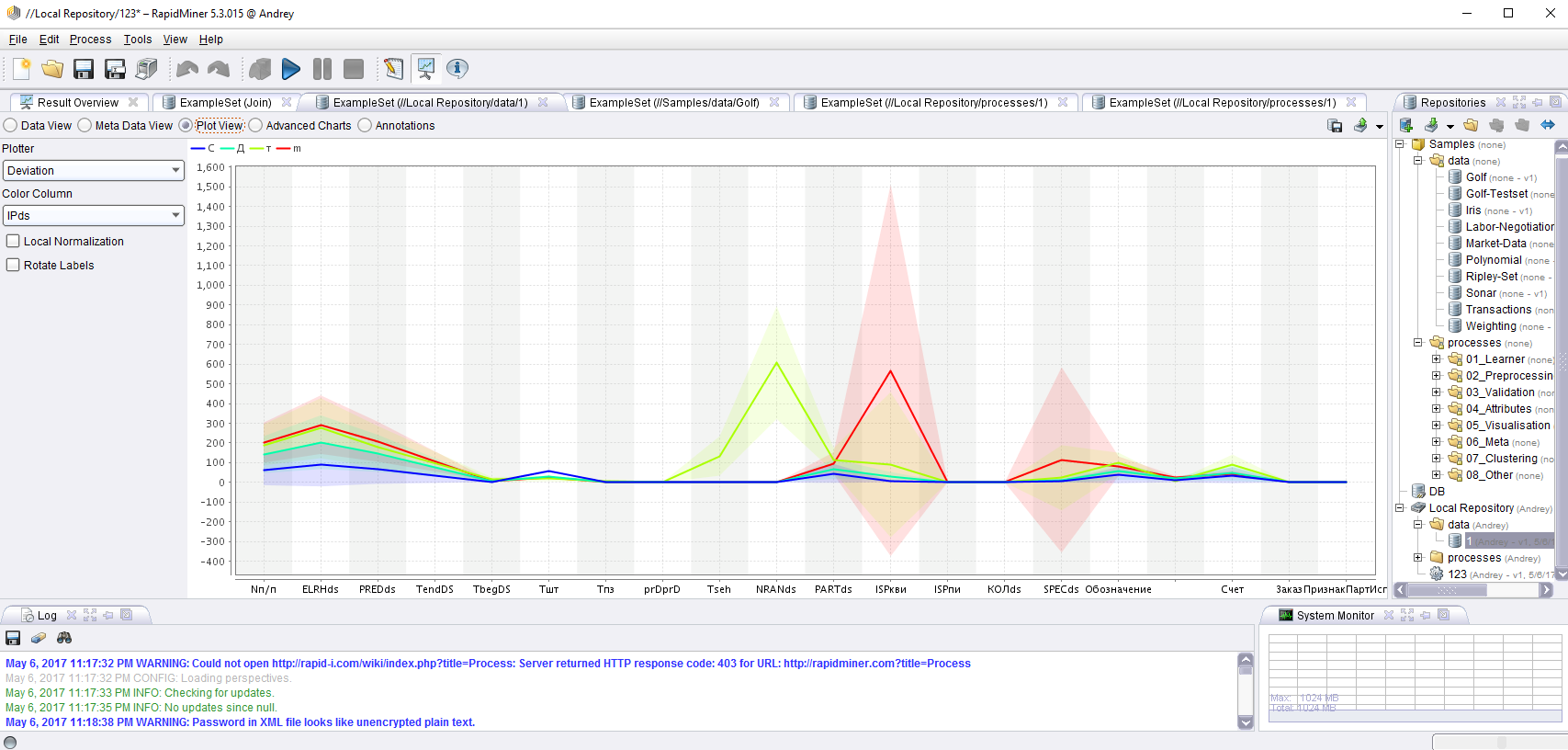
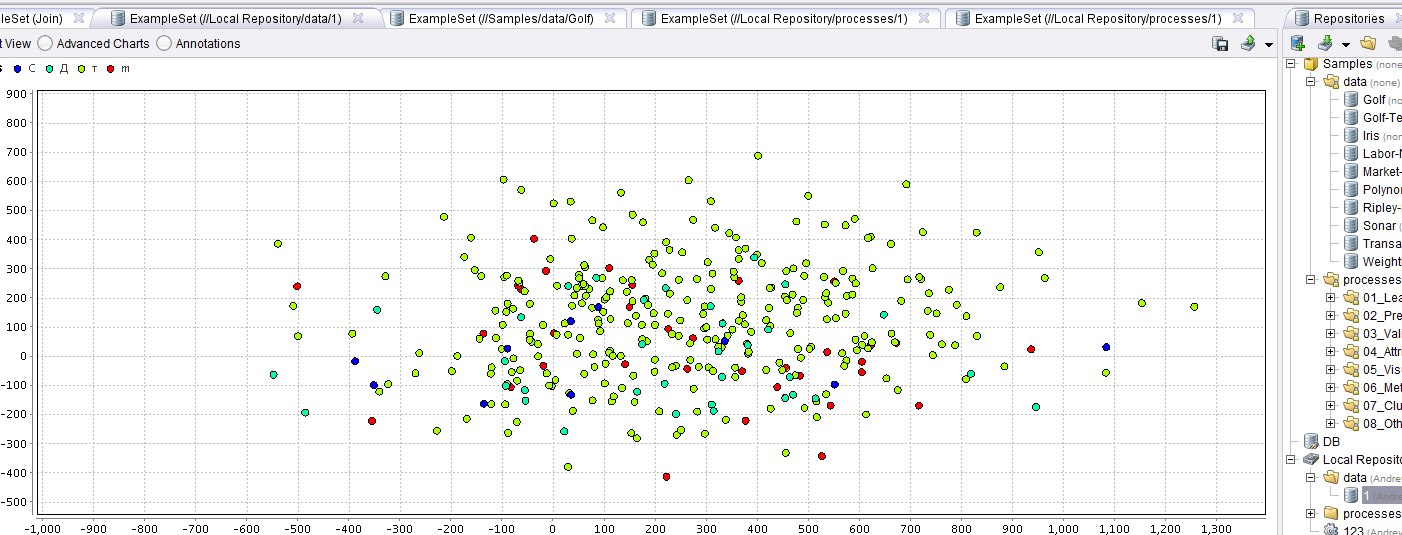
После создания процесса и его запуска можно построить графики разброса величин и многое другое.
Кроме скачивания дистрибутива программы с официального сайта https://my.rapidminer.com/nexus/account/index.html#downloads , также можно скачать git репозиторий и собрать проект с помощью apache ant.
git clone https://github.com/rapidminer/rapidminer-5.git
ant build
ant release.makePlatformIndependent



